Introduction
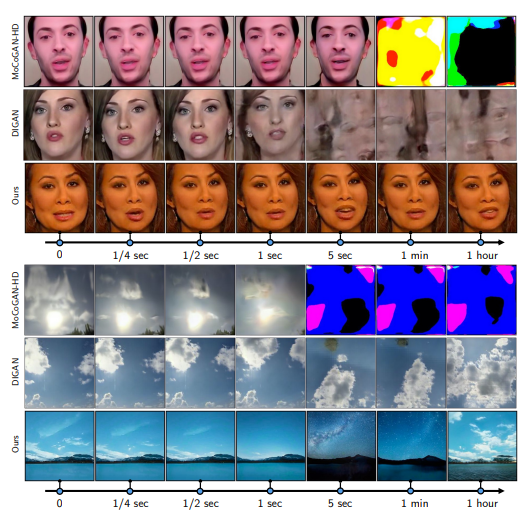
이미지 생성에 비해 비디오생성은 성공이 없었고 실제 데이터셋에 맞추기 힘들었다.
일반적으로 비디오를 이산적 이미지로 다뤘는데, 고화질로 오랜기간 뽑기 힘듬
→ 비디오 그 자체, 연속 signals x(t)로 다룸
gan base synthesis framework
sin/cos positional embedding → 비디오는 주기성 x 알맞지 x
→ positional embedding with time-varying wave parameters (depend on motion information, sampled uniquely for diffrent video)
→ padding less conv1d-based model (장기기억 문제 완화)
적절한 샘플링이 필요
→ extremely sparse video 에서 가능 (as few as 2 frames per clip)
redesign discriminator in the new samplie pipeline
→ discriminator based conv-3d 는 sequence가 길어질떄 동떨어지는 frame 생성
→ hypernetwork-based modulation : discriminator가 flexible하게 프레임 처리
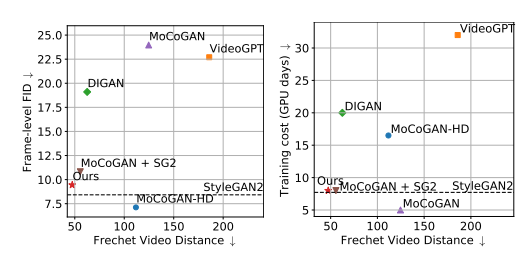
기존의 학습 방식과 5프로 정도의 cost 차이
Related work
video synthesis
video prediction : 기존은 이전 프레임으로 다음 프레임 예측 → requrrent계열의 문제가 발생했지만 adversiral loss로 나아짐
video interpolation : video sr
MoCoGAN, TGAN : generator input → content code + motion code
SVGAN : + self supervision loss
MoCoGAN-HD, StyleVideoGAN : stylegan2로 motion code 간접적으로 학습
Neural Representation
뉴럴넷으로 이미지, 비디오, 오디오, 3D 같은 신호 표현
concurrent work
DIGAN : 영감을 많이 주었지만 우리는 motion parametrization & dual discriminator ((x1, x2, t), individual image)
Model
각각의 비디오를 x(t)로 처리 → 즉 데이터셋에서 n개의 샘플을 뽑는것
subsample에서 학습하는게 목표
$$ \begin{align*} \mathcal{D}=\left\{\boldsymbol{x}^{(i)}\right\}{i=1}^{n}= \end{align*} \begin{align*} \left\{\left(\boldsymbol{x}{t_{0}}^{(i)}, \ldots, \boldsymbol{x}{t{\ell_{i}}}^{(i)}\right)\right\}_{i=1}^{N} \end{align*} $$
$N$: total number of video
$t_j$: j-th frame
$l_i$:total frame in the i-th video
generator
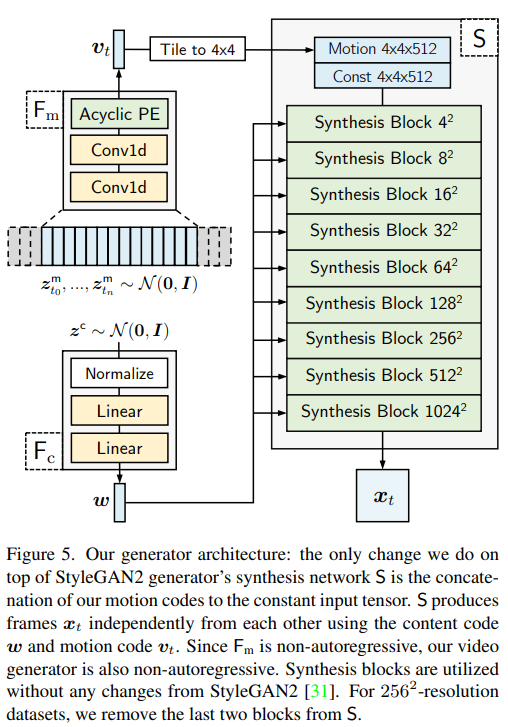
$F_m$
1. 떨어진 노이즈를 분포에서 샘플링 ($t_0 = 0$)
$$ \begin{align*}z_{t_{0}}^{\mathrm{m}}, \ldots, z_{t_{n}}^{\mathrm{m}} \sim \mathcal{N}(\mathbf{0}, \boldsymbol{I})\end{align*} $$
2. positioned at distance
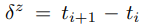
3. proccess conv1d mapping network $F_m$ → $u_{t_0}, ... , u_{t_n}$
Acyclic positional encoding
일반적으로 cyclic한 포지셔널 임베딩 사용했었음 → 이미지에서는 주기를 넘지 않음
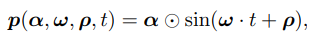
→ 여전히 주기성을 갖고있음
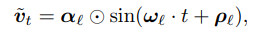
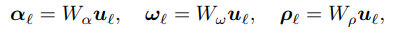
$\tilde{\boldsymbol{v}}_{t}$는 sparse 하게 가져왔기 떄문에 stitch 해줘야 좋은 결과를 얻을 수 있음
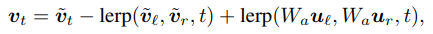
0으로 수렴하는 구간 ${t_0, t_1,..., t_n, ...}$이 있어서 $W$로 projection
$u_t = lerp(u_l, u_r, t)$ 로 시도했으나 cyclicity 는 없앴으나 품질이 좋지 않았음
(샘플링 간격이 좁았을때 이미지가 sharp 해짐, 간격이 넓을떄는 high-frequency 모션을 잘 생성하지 못함)
discriminator
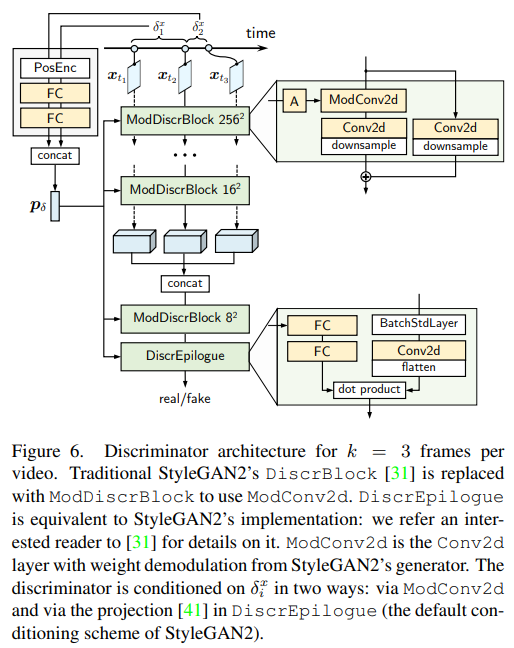
기존의 discriminators들은 이미지수준과 비디오수준 두가지로 작동했음
→ 극도로 sparse 한 video에서 학습했으므로 frame간 시간차이를 조건으로 가진 전체적인 hypernetwork-based discriminator$D(x_{t_1}, ..., x_{t_k})$ 필요
- $D_b$
- convolutional head에 3D feature vector를 concat한 후 input으로 줌
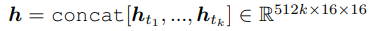
- $D_h$
- distance information \delta_{1}^{x}, \ldots, \delta_{k-1}^{x} 를 이용
- positional encoding을 해준 후 2개의 FC layer에 통과
- 각 결과물 $\boldsymbol{p}\left(\delta_{1}^{x}\right), \ldots, \boldsymbol{p}\left(\delta_{k-1}^{x}\right)$ 을 concat한 후 modulate하는데 사용
generator에서는 $w$를, discriminator에서는 $p_\delta$ 를 modulation
각각의 convolution layer를 modulate하지 않는데, ModConv2d가 Conv2d보다 25% 무거운 연산
sparse training

video synthesis에서 k-1개의 previous frame이 있는 k frame만 존재하면 생성 가능하다
→ 즉 두개만 있으면 됨
다른모델과 달리 non-autoregressive → 비디오가 길어진다고 해서 추가 컴퓨팅 자원 필요 x
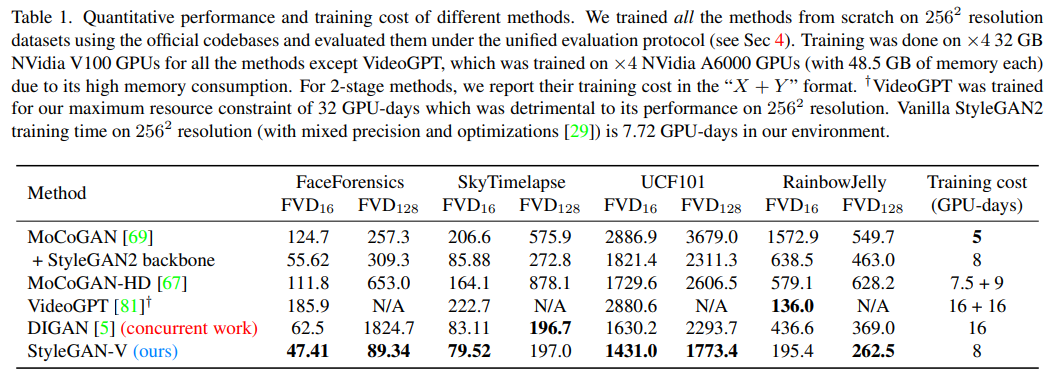
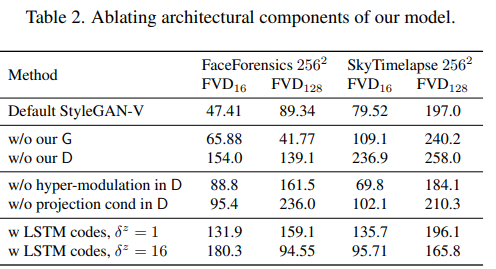
Ablation Study
'논문리뷰' 카테고리의 다른 글
| I-Bert 논문리뷰 (0) | 2022.03.19 |
|---|---|
| DETR 논문리뷰 (0) | 2022.03.19 |


댓글